




OpenCLGrid Design Considerations
In this article, we want to reveal our thoughts and considerations about performance and the related design in CONRAD. Two technologies have to be evaluated in terms of performance: the used programming language Java and the low-level API for heterogeneous computing in parallel: OpenCL. This is not only a summary of existing results, but also a starting point for further and deeper performance improvements.
Java
Evaluating Java's instanceof and its alternatives
 OpenCLGrid1D, OpenCLGrid2D, and OpenCLGrid3D, and the PointwiseIterator class use frequently Java's instanceof. Therefore, a detailed consideration in terms of performance is appropriated.
OpenCLGrid1D, OpenCLGrid2D, and OpenCLGrid3D, and the PointwiseIterator class use frequently Java's instanceof. Therefore, a detailed consideration in terms of performance is appropriated.
There are four approaches for this goal (demo source code can be found 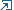 here):
here):
- instanceof implementation (as reference)
- object orientated via an abstract class and @Override a test method
- using an own type implementation
- getClass() == _.class implementation
The results are shown in the table below (Java 1.8 without further optimizations on Mac OS X 10.10, run time for 10^9 iterations for distinguishing two randomly inherited classes):
Because all alternatives seems to be not as performant (for less then 9 different classes), instanceof is a valid and suitable approach for the OpenCL grids and their operators.
The performance advantage of the type-implementation at more then 9 classes is related to the fact, that switch cases can be used, whereas instanceof and getclass require more and more complex if-then-else trees.
JOCL
JOCL from jogamp.org offers the interface Java/OpenCL. There is another JOCL framwork, but they are developed independently from each other.
Pre-allocating CLProgram, CLKernel, and CLCommandQueue
We pre-allocate CLProgram, CLKernel, and CLCommandQueue objects while the kernel is called the first time for a faster computation after the first kernel call. This leads to a longer run time for the first kernel call, but dramatically reduced run time after the first call.
This is done by a Singleton-like instantiation: If there is already an instance in the corresponding hash map, this is returned, otherwise it is created in dependency of device, kernel(name), and/or program.
A performance leak was device.createCommandQueue() which was called in every kernel run. Now we pre-allocate the command queue in the same way as the kernel and program.
This reduces the run time for handling the OpenCL command queue: A pure device.createCommandQueue() call lasts 10822 microseconds on a reference system. The mentioned first call, the preallocation, needs slightly more (11335 microseconds), but all further calls are reduced to a run time of 6 microseconds.
OpenCL
Finding the best work group size by experiment
Each OpenCL kernel has its own optimal (local) work group size. This is determined by experiment during the first kernel call. Besides allocating the magnitudes mentioned in previous section, this leads to an even worse run time for the first kernel call. But the work group size cannot be determined in advance, because it is platform and device dependent.
The approach is similar to the one for kernel, program, and program queue.
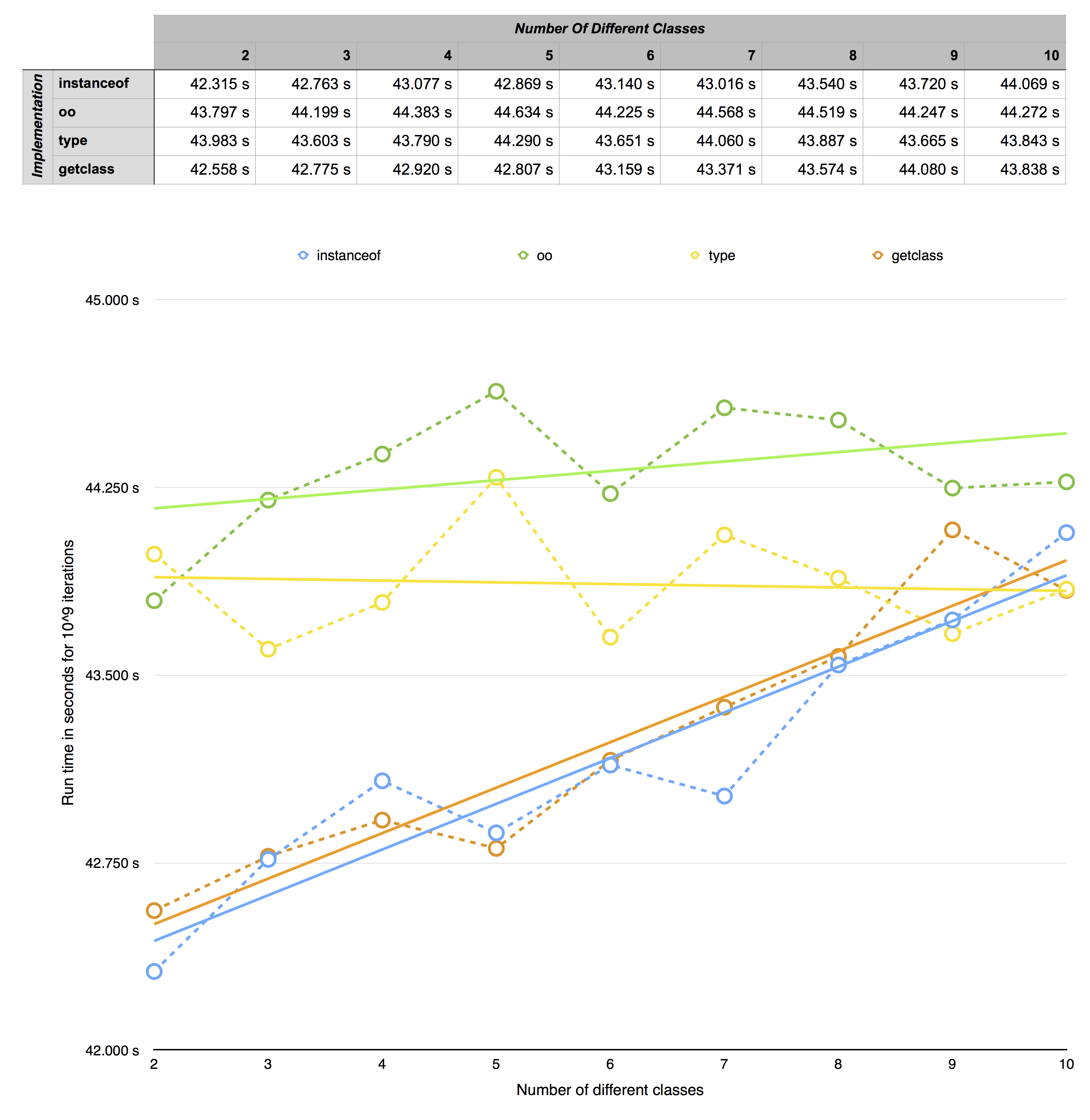
Example: For the sum-kernel running on a NVIDIA GeForce GT 120 with 512 MB we can find these configuration combinations and the related run time:
Remark: Please consider the log_2 scale for problem size and kernel size, while the time is on linear scale!
Vector Datatypes
OpenCL offers vector data types like float4, int8, etc. Not only on CPUs, but also on GPUs vectorized data types promise a slightly better performance (see e.g. here). But this is not straight forward, especially it is different for CPUs which have mostly a SIMD instruction set, and GPUs:
"However, using types wider than the underlying SIMD is somewhat similar to loop-unrolling. This might be performance advantageous in some cases, but also increases register pressure, so some experimenting is required."
Therefore, a more detailed consideration is not interesting, because the expected performance impact is too small with respect to the effort.
Local Memory
In the OpenCL architecture local memories offer a better throughput than the global equivalent (see e.g. here, p. 12). But CPU have (depending on the platform) only a limited work-group size for that specific kernel (reduced to 1), if there is a barrier inside. However, CLK_LOCAL_MEM_FENCE is necessary for implementing computations using local memory (more about this effect can be found here).