




Implementation of ART
We have introduced the Algebraic Reconstruction Technique (ART) method for Computation Tomography (CT) image reconstruction and have displayed some nice results for  parallel beam CT image reconstruction. Except parallel beam, ART can also be extended into fan beam or cone beam CT image reconstruction and its computation speed can be improved with OpenCL girds. Here, an implementation of ART for more general application is shown.
parallel beam CT image reconstruction. Except parallel beam, ART can also be extended into fan beam or cone beam CT image reconstruction and its computation speed can be improved with OpenCL girds. Here, an implementation of ART for more general application is shown.
Abstract Classes: Projector and Backprojector
In order to keep the ART applicable to different image acquisition geometries, corresponding projectors and backprojectors are necessary. Thus, abstract classes were introduced in our codes.
public abstract class Projector {
public abstract Grid project(Grid grid, Grid sino);
public abstract Grid project(Grid grid, Grid sino, int index);
}
Subclasses have to be implemented to extend the abstract classes for parallel beam, fan beam and cone beam geometries and for each acquisition geometry, ray driven projector and pixel driven backprojector are needed. Here the image data is stored in grid and the sinogram is stored in sino. Besides, if we want to project the image at only one certain angle to get a 1D sinogram or only this 1D sinogram is backprojected, then project can be called with a third argument index, the angle index.
Additionally, the pre-implemented abstract Grid class of CONRAD is used instead of Grid1D, Grid2D and Grid3D. This way, the exactly same form of ART Projector can represent different projectors and backprojectors for different geometries (e.g. 2D – fan beam, 3D – cone beam).
For example:
public Grid reconstruct(Grid originalSinogram, Grid recon, Grid imageUpdate, Grid localImageUpdate, Grid diff)
In this function, we need to project the current reconstruction Grid recon at projection angle index. The result is stored in Grid diff.
diff = projector.project(recon, diff, index);
Which projector and grids are used for this operation depends on the instantiation of ART, where the constructor is called with specific choice of the abstract classes projector and backprojector.
// constructor in ART.java
public ART(Projector projector, Backprojector backprojector){
this.projector = projector;
this.backprojector = backprojector;
}
ART and OpenCL
As mentioned above, the ART implementation works for different acquisition geometries. This also holds for OpenCL implementation. The instantiations of the subclasses in the main function are different, however the corresponding call of ART and its methods are identical to the CPU based version.
// instantiation of ART in main of PerformReconstruction.java using OpenCL
projector = new ParallelProjectorRayDrivenCL(maxTheta, deltaTheta, maxS, deltaS);
backprojector = new ParallelBackprojectorPixelDrivenCL(originalSinogram,x ,y);
art = new ART(projector, backprojector);
// call of ART method
recon = (Grid2D) art.reconstruct(originalSinogram, recon, imageUpdate, localImageUpdate, sino);
The proposed structure would also be operational with OpenCL Grids to further improve computation speed.
To run the code on the GPU, we use specific subclasses to abstract projector and backprojector. These subclasses handle the definition of an OpenCL context, selection of the OpenCL device and finally use a kernel function (*.cl) to execute the source code for a projection or backprojection. So far, kernels for ray driven projection and pixel driven backprojection for both parallel and fan beam cases are created. The kernel source code is only read by the host code (*.java) during runtime.
// load sources, create and build program
program = context.createProgram(this.getClass().getResourceAsStream("FanBackprojectorPixelDriven.cl")).build();
After the program has been generated from the *.cl file, the kernel can be created and parameters can be set. The final execution is directed by the command queue, where the kernel is run.
// create kernel
CLKernel kernel = program.createCLKernel("backprojectPixelDriven2DCL");
// create CommandQueue
CLCommandQueue queue = device.createCommandQueue();
queue.putWriteImage(sinoGrid, true).finish()
.put2DRangeKernel(kernel, 0, 0, globalWorkSizeX, globalWorkSizeY,localWorkSize, localWorkSize).finish().
putReadBuffer(imgBuffer, true).finish();
Usage of ART implementation
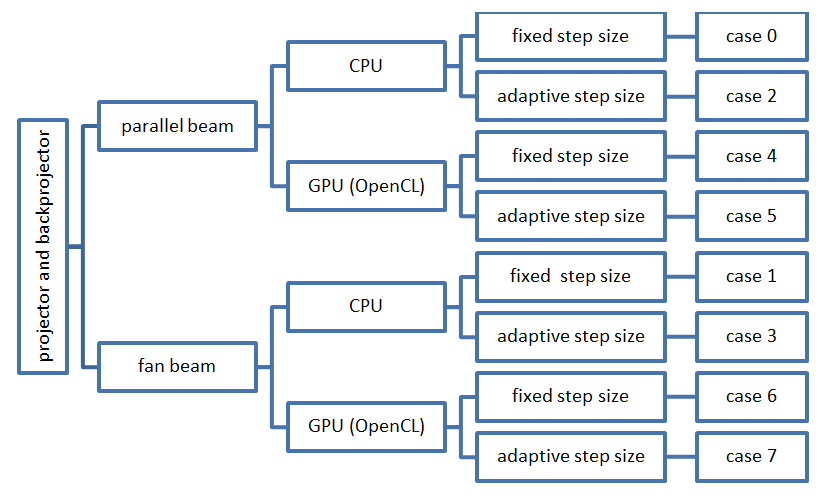
To run our implementation of ART, we create a main function in PerformReconstruction.java. There, the sinogram of the Shepp-Logan phantom and all grids are generated. The grids are created in the beginning to avoid costly memory allocation during the reconstruction process. The instantiation of the projector, backprojector and ART is performed in a switch case statement. As shown in Fig. 1, eight different cases can be distinguished for parallel or fan beam geometry, CPU or GPU based computation and adaptive or fixed step size.
// instantiation of ART in main of PerformReconstruction.java
projector = new ParallelProjectorRayDriven(maxTheta, deltaTheta, maxS, deltaS);
backprojector = new ParallelBackprojectorPixelDriven(originalSinogram);
art = new ART(projector, backprojector);
// call of ART method
recon = (Grid2D) art.reconstruct(originalSinogram, recon, imageUpdate, localImageUpdate, sino);
To alter the parameters or geometry of the reconstruction, it is thus sufficient to adapt the main method. The ART algorithm is programmed so as to function for arbitrary settings.
 |
Results and Discussion
Fig 2 shows the results of the above iterative reconstruction implementations. In the table, the average pixel error after 15 iterations and the average time per iteration are displayed. The results indicate that, for Fixed Step Size cases, our ART implementation with OpenCL doesn't run faster than ART CPU, which maybe result from the frequent data transfer between CPU and OpenCL memory. However, for Adaptive Step Size cases, which require much more computation, our ART implementation with OpenCL has an obvious speed up than ART CPU.
The implementation of ART is versatile and can handle different types of projectors and backprojectors, not only regarding the geometry, but also CPU and GPU based computation. It is suited to test further implementations (e.g. cone beam geometry). The management of memory supports OpenCL application, as grids are reused rather than newly created.
 |
Code
For the full source codes, please refer to folder "FlatPanelProject" in CONRAD.
Authors
Anja Jäger, Tilmann Hübner, Karoline Kallis, Hamidreza Moghadas, Yixing Huang, Andreas Maier