
Friedrich-Alexander-Universität Erlangen
Lehrstuhl für Mustererkennung
Martensstraße 3
91058 Erlangen
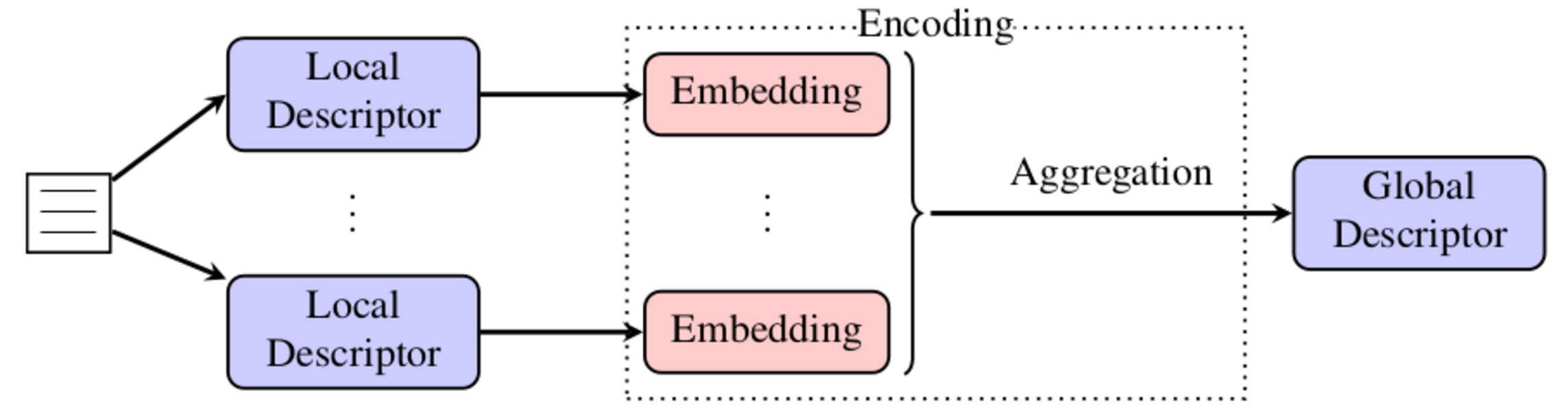
The encoding of local features is an essential part for writer identification and writer retrieval. While CNN activations have already been used as local features in related works, the encoding of these features has attracted little attention so far. In this work, we compare the established VLAD encoding with triangulation embedding. We further investigate generalized max pooling as an alternative to sum pooling and the impact of decorrelation and Exemplar SVMs. With these techniques, we set new standards on two publicly available datasets (ICDAR13, KHATT).
In contrast to physiological biometric identifiers like fingerprints or iris scans, handwriting can be seen as a behavioral identifier. The process of writing is heavily influenced by factors like schooling or aging. Writer identification is the task of finding an individual scribe in a large data corpus. Typical applications lie in the fields of forensics or security. However, writer identification recently also raised interest in the analysis of historical texts, where they might give new insights of life in the past.
Group members in this project:  Vincent Christlein
Vincent Christlein
The encoding of local features is an essential part for writer identification and writer retrieval. While CNN activations have already been used as local features in related works, the encoding of these features has attracted little attention so far. In this work, we compare the established VLAD encoding with triangulation embedding. We further investigate generalized max pooling as an alternative to sum pooling and the impact of decorrelation and Exemplar SVMs. With these techniques, we set new standards on two publicly available datasets (ICDAR13, KHATT).
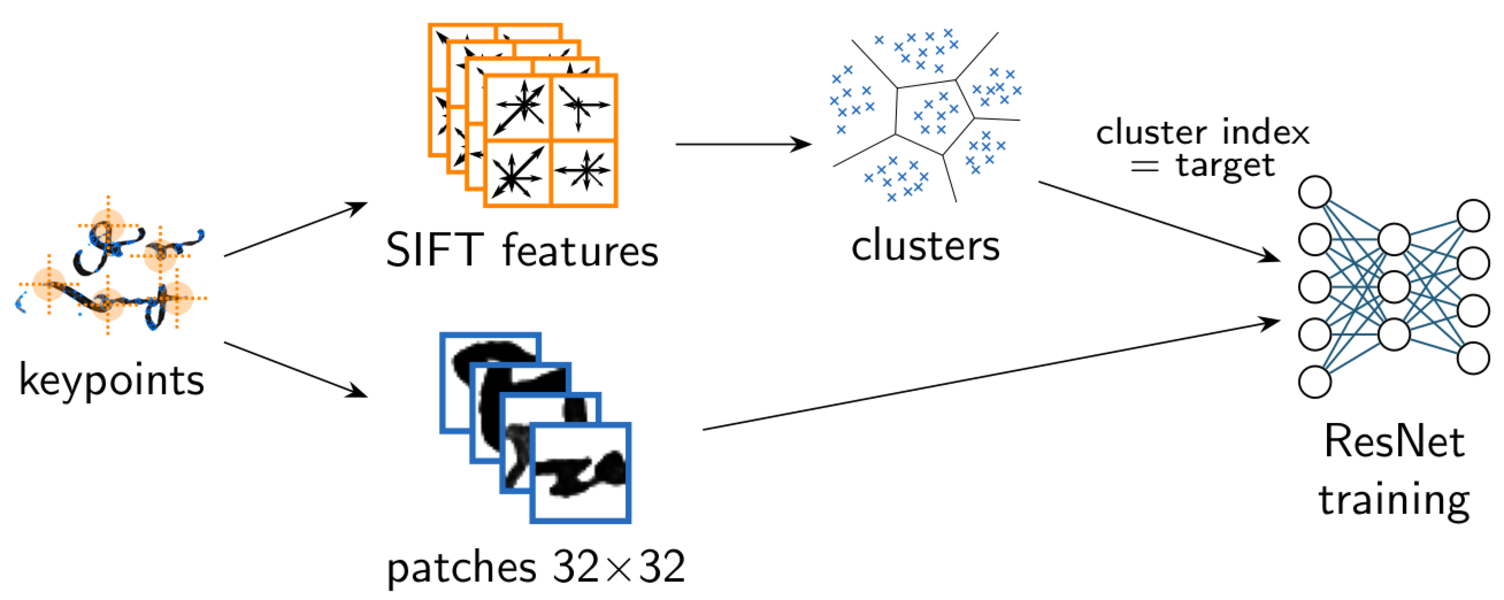
Deep Convolutional Neural Networks (CNN) have shown great success in supervised classification tasks such as character classification or dating. Deep learning methods typically need a lot of annotated training data, which is not available in many scenarios. In these cases, traditional methods are often better than or equivalent to deep learning methods. In this paper, we propose a simple, yet effective, way to learn CNN activation features in an unsupervised manner. Therefore, we train a deep residual network using surrogate classes. The surrogate classes are created by clustering the training dataset, where each cluster index represents one surrogate class. The activations from the penultimate CNN layer serve as features for subsequent classification tasks. We evaluate the feature representations on two publicly available datasets. The focus lies on the ICDAR17 competition dataset on historical document writer identification (Historical-WI). We show that the activation features trained without supervision are superior to descriptors of state-of-the- art writer identification methods. Additionally, we achieve comparable results in the case of handwriting classification using the ICFHR16 competition dataset on historical Latin script types (CLaMM16).
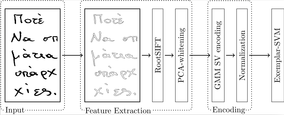
This paper describes a method for robust offline writer identification. We propose to use RootSIFT descriptors computed densely at the script contours. GMM supervectors are used as encoding method to describe the characteristic handwriting of an individual scribe. GMM supervectors are created by adapting a background model to the distribution of local feature descriptors. Finally, we propose to use Exemplar-SVMs to train a document-specific similarity measure. We evaluate the method on three publicly available datasets (ICDAR / CVL / KHATT) and show that our method sets new performance standards on all three datasets. Additionally, we compare different feature sampling strategies as well as other encoding methods.
In recent years, Automatic Writer Identification (AWI) has received a lot of attention in the document analysis community. However, most research has been conducted on contemporary benchmark sets. These datasets typically do not contain any noise or artefacts caused by the conversion methodology. This article analyses how current state-of-the-art methods in writer identification perform on historical documents. In contrast to contemporary documents, historical data often contain artefacts such as holes, rips, or water stains which make reliable identification error-prone. Experiments were conducted on two large letter collections with known authenticity and promising results of 82% and 89% TOP-1 accuracy were achieved.

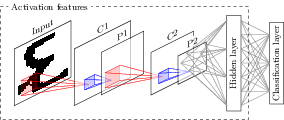
Convolutional neural networks (CNNs) have recently become the state-of-the-art tool for large-scale image classification. In this work we propose the use of activation features from CNNs as local descriptors for writer identification. A global descriptor is then formed by means of GMM supervector encoding, which is further improved by normalization with the KL-Kernel. We evaluate our method on two publicly available datasets: the ICDAR 2013 benchmark database and the CVL dataset.
→ Competition Winner: ICDAR 2015 Competition on Multi-Script Writer Identification and Gender Classification (Task 1)
→ Best Poster Award for a very significant contribution in the field of document analysis and recognition
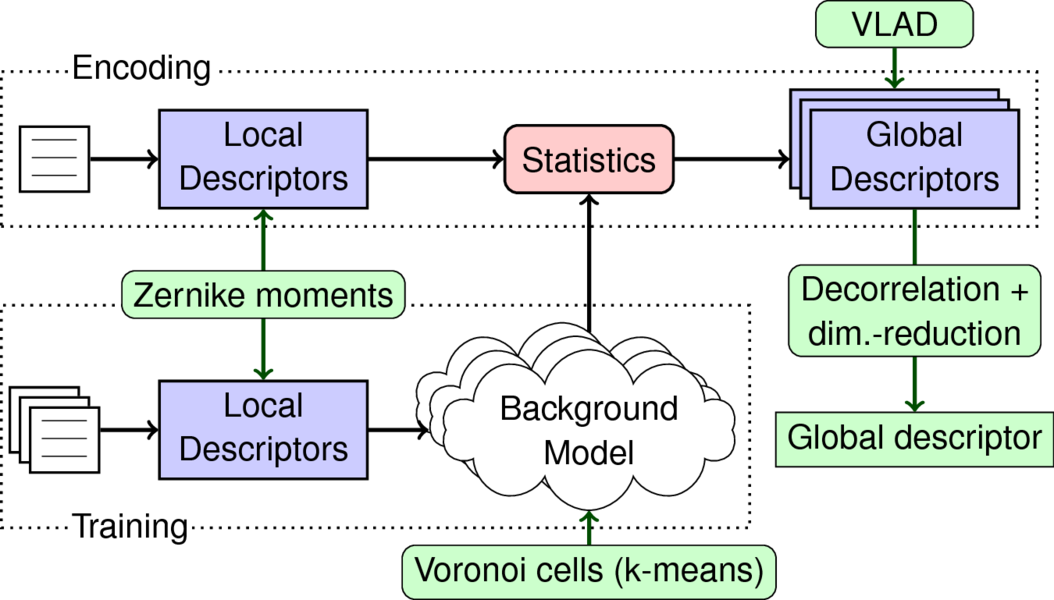
Local feature descriptors in combination with bag of (visual) words have recently become the state of the art in writer identification. In this work we propose the use of Zernike moments evaluated at the contours of the script as local descriptor. We then form a global descriptor by encoding the extracted Zernike moments into Vectors of Locally Aggregated Descriptors (VLAD).
→ Competition Winner: ICFHR2014 Competition on Arabic Writer Identification Using AHTID/MW and KHATT Databases,
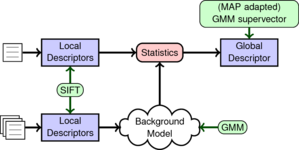
This paper proposes a new system for offline writer identification and writer verification. The proposed method uses GMM supervectors to encode the feature distribution of individual writers. Each supervector originates from an individual GMM which has been adapted from a background model via a maximum-a-posteriori step followed by mixing the new statistics with the background model.
→ Competition Winner: ICFHR2014 Competition on Arabic Writer Identification Using AHTID/MW and KHATT Databases,
This paper proposes a new system for offline writer identification and writer verification. The proposed method uses GMM supervectors to encode the feature distribution of individual writers. Each supervector originates from an individual GMM which has been adapted from a background model via a maximum-a-posteriori step followed by mixing the new statistics with the background model.
→ Competition Winner: ICDAR 2015 Competition on Multi-Script Writer Identification and Gender Classification (Task 1)
→ Best Poster Award for a very significant contribution in the field of document analysis and recognition
Local feature descriptors in combination with bag of (visual) words have recently become the state of the art in writer identification. In this work we propose the use of Zernike moments evaluated at the contours of the script as local descriptor. We then form a global descriptor by encoding the extracted Zernike moments into Vectors of Locally Aggregated Descriptors (VLAD).
Convolutional neural networks (CNNs) have recently become the state-of-the-art tool for large-scale image classification. In this work we propose the use of activation features from CNNs as local descriptors for writer identification. A global descriptor is then formed by means of GMM supervector encoding, which is further improved by normalization with the KL-Kernel. We evaluate our method on two publicly available datasets: the ICDAR 2013 benchmark database and the CVL dataset.
In recent years, Automatic Writer Identification (AWI) has received a lot of attention in the document analysis community. However, most research has been conducted on contemporary benchmark sets. These datasets typically do not contain any noise or artefacts caused by the conversion methodology. This article analyses how current state-of-the-art methods in writer identification perform on historical documents. In contrast to contemporary documents, historical data often contain artefacts such as holes, rips, or water stains which make reliable identification error-prone. Experiments were conducted on two large letter collections with known authenticity and promising results of 82% and 89% TOP-1 accuracy were achieved.
This paper describes a method for robust offline writer identification. We propose to use RootSIFT descriptors computed densely at the script contours. GMM supervectors are used as encoding method to describe the characteristic handwriting of an individual scribe. GMM supervectors are created by adapting a background model to the distribution of local feature descriptors. Finally, we propose to use Exemplar-SVMs to train a document-specific similarity measure. We evaluate the method on three publicly available datasets (ICDAR / CVL / KHATT) and show that our method sets new performance standards on all three datasets. Additionally, we compare different feature sampling strategies as well as other encoding methods.
Deep Convolutional Neural Networks (CNN) have shown great success in supervised classification tasks such as character classification or dating. Deep learning methods typically need a lot of annotated training data, which is not available in many scenarios. In these cases, traditional methods are often better than or equivalent to deep learning methods. In this paper, we propose a simple, yet effective, way to learn CNN activation features in an unsupervised manner. Therefore, we train a deep residual network using surrogate classes. The surrogate classes are created by clustering the training dataset, where each cluster index represents one surrogate class. The activations from the penultimate CNN layer serve as features for subsequent classification tasks. We evaluate the feature representations on two publicly available datasets. The focus lies on the ICDAR17 competition dataset on historical document writer identification (Historical-WI). We show that the activation features trained without supervision are superior to descriptors of state-of-the- art writer identification methods. Additionally, we achieve comparable results in the case of handwriting classification using the ICFHR16 competition dataset on historical Latin script types (CLaMM16).